并行编程-内存模型(Memory Model)
文章目录
先看两个问题
std::shared_ptr
::use_count long use_count() const noexcept;
返回管理当前对象的不同 shared_ptr 实例(包含 this )数量。若无管理对象,则返回 0。多线程环境下, use_count 返回的值是近似的(典型实现使用 memory_order_relaxed 加载)
cppreference
为什么这里的返回值是近似的。当然只是指 use_count() 这个成员函数返回的值不一定是准的(连带着使用这个的 unique() 也是不准的),但 shared_ptr 内部对引用计数的使用都是正确的,如正确的释放已无人持有的对象。
还有一个 golang 用双检锁实现的单例模式
| |
为什么这个单例的实现理论上仍然是线程不安全的。
这两个例子分别展示了多线程下变量的可见性和处理器指令执行顺序不同而导致的问题,属于内存模型的范畴。
内存模型(memory model)是什么
In computing, a memory model describes the interactions of threads through memory and their shared use of the data.
wikipedia
直译: 在计算机中,内存模型描述了线程通过内存的相互作用以及它们对数据的共享使用。
这是维基百科给出的定义,感觉说的有些笼统
A memory consistency model, or, more simply, a memory model, is a specification of the allowed behavior of multithreaded programs executing with shared memory. For a multithreaded program executing with specific input data, it specifies what values dynamic loads may return and what the final state of memory is.
A Primer on Memory Consistency and Cache Coherence
这是 APMCCC 里给的解释,感觉清晰一些。大概意思是内存模型描述了多线程程序访问共享内存时应该遵守的一些行为,如对于给定的输入,在不同条件下的输出和最终在内存中的状态应该是可以被确定的。
因为从代码文本到真正在机器上运行产生效果,中间至少会经过编译至二进制和执行指令等一系列涉及到软件和硬件的过程,而这个过程每一步可能都会对最后的执行效果产生影响,所以内存模型可以自然的分为硬件内存模型(hardware memory model)和软件内存模型(software memory model)
cpu 重排
硬件内存模型一般就是指 cpu 层面的内存模型。cpu 在执行指令时,可能会为了性能而不按照代码顺序执行,比如
| |
假设有两个线程在分别执行 write() 和 read() 两个函数,step 3 的输出可能会是 0。因为写入对 cpu 来说是一个相对比较耗时的操作,至少会消耗10~100时钟周期,cpu 在等待 step 1 执行完成的时候,可以并行执行 step 2。当 step 2 先于 step 1 完成时,外界看到的仿佛就是 step 2 先于 step 1 执行一样。这种操作对于单线程是完全没有问题的,因为 data 和 flag 在数据上没有依赖,无论先执行哪个都不影响后续的 do_someting() 最终结果。但在多线程的情况下就可能出现上面说到的问题。把读写顺序排列一下可以得到 Store-Store、Store-Load、Load-Load 和 Load-Store 四种组合,例子中的现象就属于 Store-Store 的一个重排,任意一种重排都会导致程序的正确性无法保证。自然而然,就需要一套规则,让上层开发者知道哪些重排行为是可能发生的,哪些不会发生,避免开发者踩坑。从这个角度来看,抽象出的这套规则也就是内存模型。接下来说一下一些常见的内存模型。
顺序一致性(Sequential Consistency)
Lamport (1979) 论文中的定义:
the result of any execution is the same as if the operations of all the processors were executed in some sequential order,and the operations of each individual processor appear in this sequence in the order specified by its program.
直译的话
任何执行的结果都与所有处理器的操作按某种顺序执行的情况相同,而且每个处理器的操作都按其程序指定的顺序出现在这个序列中。
维基百科有另一种解释
(并发程序在多处理器上的)任何一次执行结果都相同,就像所有处理器的操作按照某个顺序执行,各个微处理器的操作按照其程序指定的顺序进行。换句话说,所有的处理器以相同的顺序看到所有的修改。读操作未必能及时得到此前其他处理器对同一数据的写更新。但是各处理器读到的该数据的不同值的顺序是一致的。
这个感觉会更好理解。
总的来说,顺序一致性模型是最符合直觉的一种模型,四种读写顺序都不允许重排,仿佛存储与 cpu 之间有一个唯一的开关,所有的访问都串行经过这个开关,同时也对程序员比较友好。不过采用这种模型后性能就会出现一些问题,如下图[1],横坐标是功能不同的示例程序,纵坐标是归一化的执行时间
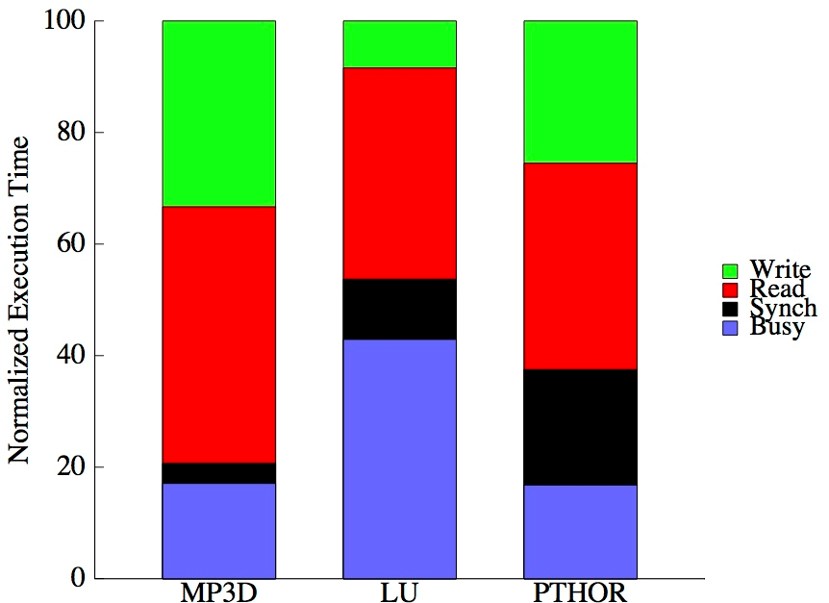
可以看到 cpu 实际的执行时间占比只有 17% ~ 42%,非常低。所以一般实现上都采用要求更宽松的模型
完全存储排序(Total Store Ordering)
TSO 模型只有一点与 SC 模型不同,它允许 Store-Load 的重排,相比 SC 模型的要求宽松一些,也就是可以在写操作未完成前执行后续的读操作,目前 Intel 的处理器就被认为是实现的 TSO 模型。允许的好处是可以有效的把写入耗时隐藏起来。看下性能对比,如下图[1],Base 是 SC 的数据,WR 是 TSO 的数据。
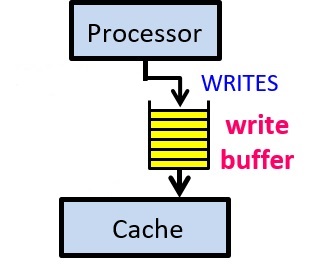
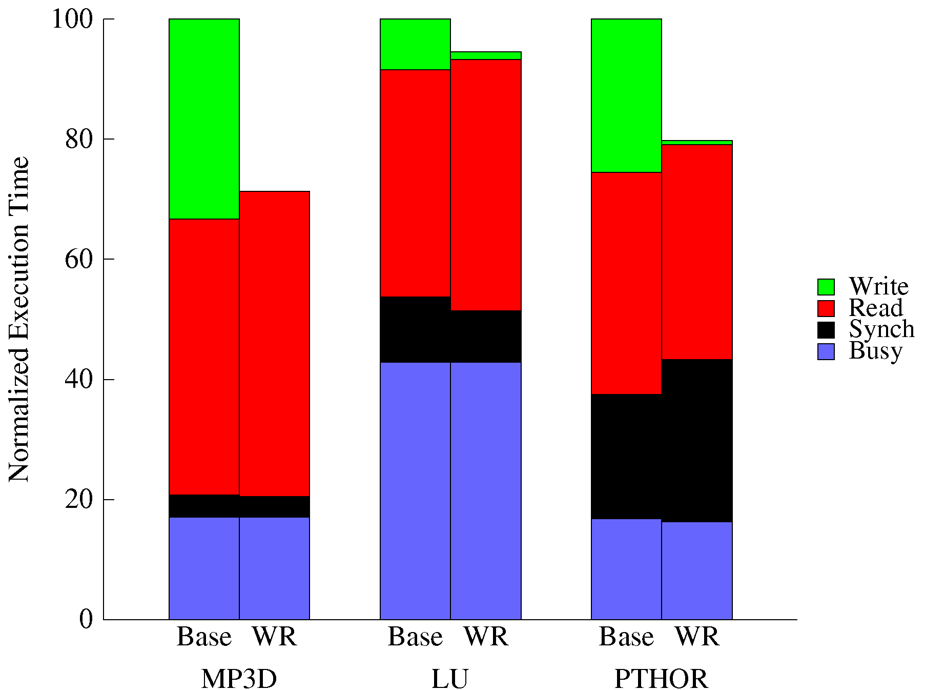 可以很明显的发现,写入耗时没了,也就提高了 cpu 真正干活的时间占比。在实现层面,目前主流实现是在 cpu 与 L1 cache 之前加一个 buffer 的硬件,cpu 执行写入时,值写入 buffer 就立即返回,继续执行,剩余的写入过程由 buffer 完成。如下图
可以很明显的发现,写入耗时没了,也就提高了 cpu 真正干活的时间占比。在实现层面,目前主流实现是在 cpu 与 L1 cache 之前加一个 buffer 的硬件,cpu 执行写入时,值写入 buffer 就立即返回,继续执行,剩余的写入过程由 buffer 完成。如下图
部分存储排序(Partial Store Ordering)
PSO 模型的要求比 TSO 更为宽松,它允许 Store-Load 和 Store-Store 两种重排
弱序模型(Weak Ordering)
WO 是最宽松的模型,四种重排它都允许
部分处理器架构下的内存模型
如果所示,取自于 维基百科
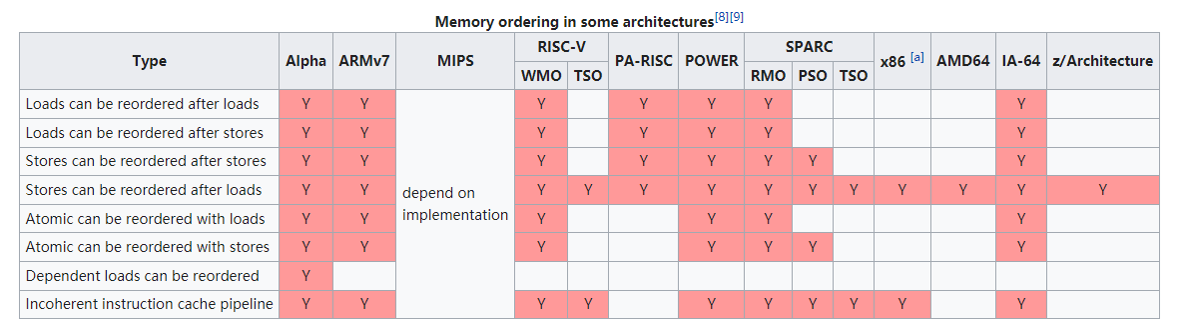 值得注意的是常用于移动端的 arm 架构,就是 WO 模型,允许所有类型的重排,所以在编写跨平台的代码时,内存模型在某些环节就需要格外注意一下。
值得注意的是常用于移动端的 arm 架构,就是 WO 模型,允许所有类型的重排,所以在编写跨平台的代码时,内存模型在某些环节就需要格外注意一下。
在要求比较宽松的模型下代码是否能正常工作
其实大部分代码并不需要像 SC 那样严格的顺序,就比如之前的例子中单独的 write 函数。但仍然有部分代码会出现与预期不一致的现象,为了解决这一类问题就需要利用 cpu 提供的一些指令,告知 cpu 某些地方不要做优化,按照代码顺序执行,这种指令被称作内存屏障/内存栅栏(barrier/fence)
Intel 提供的内存栅栏指令
SFENCE:位于指令前的写操作都在指令前完成
LFENCE:位于指令后的读操作都在指令后开始
MFENCE:位于指令前的读写操作在指令前完成,位于指令后的读写操作在指令后开始
使用这几个指令,可以将上面的代码改写为
| |
此时当 step 3 执行后一定会输出2
编译器重排
假设 cpu 不会改变执行顺序,也不一定会得到预期的结果,因为编译器在编译的过程中,同样也会对代码顺序做调整,以提高执行效率,主要是 cpu 流水线的整体效率,软件内存模型也就是指编译器和语言层面的。解决这个的重排就需要使用编译器或者语言层面提供的工具
语言标准
c++
volatile
用 volatile 修饰变量。c++ 标准保证编译器不会对 volatile 变量间的访问进行重排,言外之意就是 volatile 变量和其他变量间还是可能会重排,所以在上面那个例子中需要用 volatile 同时修饰 flag 与 data。当然 volatile 并不是专门干这个的,它也会阻止对变量的其他优化,比如生成每次都会去内存读数据而不使用寄存器的机器码。
内存屏障
在代码内添加内存屏障指令。asm volatile("": : :“memory”) 这是一条经典的 gcc 添加内存屏障的语句,把它加到 data 和 flag 之间就可以。这个仍然不是单纯为了解决这个问题的,比如它还会把所有寄存器内的值写回内存并重新读取。需要注意的是,这个仅作用于编译期,对运行时不会有任何影响.
atomic
c++11 后可以使用标准库内的 atomic。
std::atomic<T>::store
void store(T desired, std::memory_order order = std::memory_order_seq_cst) noexcept;void store(T desired, std::memory_order order = std::memory_order_seq_cst) volatile noexcept;
原子地以 desired 替换当前值。按照 order 的值影响内存。
order 必须是 std::memory_order_relaxed 、 std::memory_order_release 或 std::memory_order_seq_cst 之一。否则行为未定义。
cppreference
使用 atomic 其实是为了通过控制 order 参数控制 cpu 重排,并保证读写的原子性,其中也隐含了禁止编译器重排。所有的控制 cpu 重排的方法都隐含了禁止编译器重排。可以看到 order 的默认参数是 memory_order_seq_cst,也就是最强的约束顺序一致性。通过不同的 order 值组合,用 atomic 改写上面的例子如下
| |
memory_order_release 保证在这个变量之前的写操作都在这个变量的写操作之前完成,memory_order_acquire 保证在这个变量之后的读操作都在这个变量的读操作完成之后开始。 memory_order_relaxed 就是最宽松的内存模型,不做任何约束,atomic 只保证这个变量的原子性,一个常见的使用是搭配 fetch_add 做单纯的计数器。如果不是针对某个变量,仅仅想在某行代码处约束一下上下文可以使用
std::atomic_thread_fence(std::memory_order)
上面提到过,x86 被认为是一种 TSO 模型,所以在 x86 上实际起作用的只有 memory_order_relaxed 和 memory_order_seq_cst 。
golang
可以直接看官方文档 The Go Memory Model
简单来说就是 go 定了一些规则,符合这些的读写才会是符合预期的,这个部分没有 c++ 那么灵活。
总结
为了提高性能,在硬件和软件层面都有可能对指令进行重排。程序员为了在多线程下写出符合预期且尽可能高性能的代码就需要专门的工具禁止部分优化。
回到文章开头的两个问题,第一个 use_count() 值不准的意思是不能依赖这个具体数值去对这个对象本身做一些操作,因为它很可能是使用最宽松的内存模型读取的,在使用这个值的时候,不一定会发生或未发生一些在代码顺序上一定在它之前或之后的操作。第二个双检锁仍然不对是因为 new 可能包含三步,第一步获取内存空间,第二步初始化这部分空间,第三步返回这个空间的地址,有可能因为重排导致第三步先于第二步执行了,这样外界可能会拿到一个尚未初始化完毕的指针。但这在 x86 上是不会出现的,原因同上(当然单例模式也有更好的写法)
[1] 摘自 《Comparative evaluation of latency reducing and tolerating techniques》