原文:https://www.codeofhonor.com/blog/avoiding-game-crashes-related-to-linked-lists
使用 std::list
这有一个使用 STL 声明链表的例子:
1
2
3
4
5
| struct person {
unsigned age;
unsigned weight;
};
std::list <person*> people;
|
在往这个链表添加几个节点后,可以在内存中得到像这样的结构
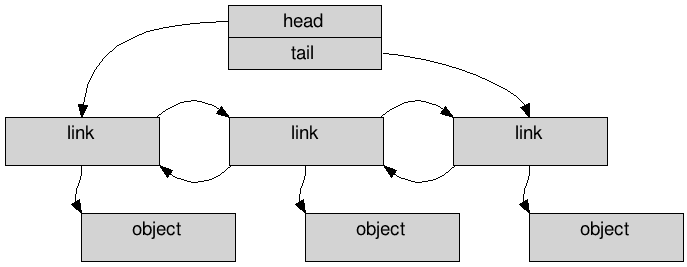
使用 c++ std::list 创建的双向链表 1
2
3
4
5
6
7
8
9
10
11
12
| // NOTE: O(N) 算法
// -- requires list scanning
// -- requires memory deallocation
void erase_person (person *ptr) {
std::list <person*>::iterator it;
for (it = people.begin(); it != people.end(); ++it) {
if (*it != ptr)
continue;
people.erase(it);
break; // assume person is only linked once
}
}
|
这种取消链接的代码太糟糕了:对于一个有 N 个节点的链表,平均需要遍历 N/2 的节点,才能找到我们想要删除的那个。这也是为什么需要随机访问时,链表不是一个好选择。
更重要的是,编写一个像上面那样的可以删除节点(list-removal)的函数是必要的,而这会增加程序员的开发时间,降低编译速度并且可能导致 bug。如果有一个更好的链表库,就完全不需要像这样的代码
使用侵入式链表
侵入式链表要求“link”字段直接嵌入要被链接的结构。在使用外部链接的链表中,它通过一个单独的对象来保存指向该对象和前一个或者后一个链接的指针,而侵入式链表则让它存在于被链接的结构中。
这有个将上面代码重新用侵入式链表实现的例子
1
2
3
4
5
6
7
| struct person {
TLink link; // The "intrusive" link field
unsigned age;
unsigned weight;
};
TListDeclare<person, offsetof(person, link)> people;
|
我使用 #define 宏来避免代码重复和拼写错误,因此我的链表定义实际是像这样:
1
| LIST_DECLARE(person, link) people;
|
与 std::list 对比,在内存布局上它分配了更少的对象
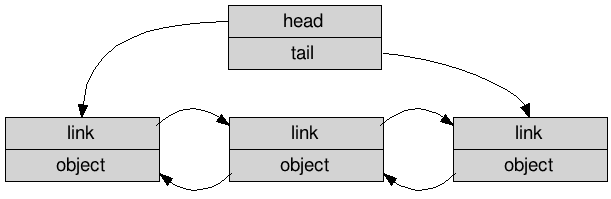
侵入式双向链表
而且从链表中删除元素既简单又快还不需要内存释放
1
2
3
4
5
6
| // NOTE: O(1) algorithm
// -- no list traversal
// -- no memory deallocation
void erase_person (person *ptr) {
ptr->link.Unlink(); // hmm... must be some magic in there
}
|
更好的是,如果你删除了一个侵入式链表的节点,它会自动的把自己移除链表:
1
2
3
4
5
| void delete_person (person *ptr) {
// automagically unlinks person record no matter
// which linked list it is contained within
delete ptr;
}
|
为什么侵入式链表是更好的
到目前为止,你可能对很多情况下为什么侵入式链表比外部链接式链表更好有所了解,我提供些我的想法:
- 因为链接字段被嵌入了对象自身,它不再需要分配内存去把一个节点链接到链表上,也不需要在解除链接时释放内存。
程序速度++,内存利用率- - 当侵入式对象存储在侵入式的链表,它可以只通过一次指针的间接寻址得到这个对象,而 std::list 则需要两次。这样可以减少的内存高速缓存(memory-cache)的抖动,可以让你的程序更快。尤其是会因内存停滞(memory stalls)导致巨大延迟的现代处理器上。
程序速度++,缓存抖动- - 我们减少了代码失败的可能,因为当链接对象时它不再需要处理 OOM 异常
代码对象大小–,代码复杂度- - 更重要的是,对象会自动从他们被链接的链表中移除,这样消除了很多常见的错误
程序可靠性++
怎么将一个对象链接到多个链表
侵入式链表的一大优点是它们仍可以正常工作。让我们看看怎么搞:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
| struct employee {
TLink<employee> employeeLink;
TLink<employee> managerLink;
unsigned salary;
};
struct manager : employee {
LIST_DECLARE(employee, managerLink) staff;
};
LIST_DECLARE(employee, employeeLink) employees;
void friday () {
// Hire Joe, a cashier
employee * joe = new employee;
joe->salary = 50 * 1000;
employees.LinkTail(joe);
// Hire Sally, a shift manager
manager * sally = new manager;
sally->salary = 80 * 1000;
employees.LinkTail(sally);
sally->staff.LinkTail(joe);
// Oops, Joe got caught with his hand in the till
delete joe;
// Now that Joe is gone, Sally has no reports
ASSERT(sally->staff.Empty());
// And she is now the only employee
ASSERT(employees.Head() == sally);
ASSERT(employees.Tail() == sally);
}
|
非常漂亮吧?你可以看到当清理时许多常见错误是怎样被避免的
我的汤里有苍蝇(There’s a fly in my soup)
有些人可能会担心他们对象现在包含了侵入式链接的字段,这个字段跟对象应该包含的数据是无关的。person 节点现在被额外的 stuff 污染了。
这确实使 leet-programmer 的工作变得更加困难,例如将记录直接写入磁盘(不能安全的写指针),使用 memcmp 比较对象等类似的东西。但是无论如何你不应该这样做,因为可靠性远比速度重要,如果你沦为需要这些 hacks 操作来提高速度的话,你的代码逻辑是需要被改进的。记得千年虫 bug!
我的对象被链接到哪
在程序中使用侵入式链表时,在声明这些结构体的同时需要声明节点被嵌入哪个链表,在大部分情况下,这是很容易的,但在某些情况下需要一些技巧:
1
2
3
4
5
6
7
8
9
10
| // Some3rdPartyHeaderYouCannotChange.h
struct Some3rdPartyStruct {
// lots of data
};
// MyProgram.cpp
struct MyStruct : Some3rdPartyStruct {
TLink<MyStruct> link;
}
LIST_DECLARE(MyStruct, link) mylist;
|
当然如果你不能控制结构体的定义也不能控制它被分配的代码,这在使用第三方库的时候是有可能的,则可以使用 std::list。
编写多线程代码的注意事项
在编写多线程代码时一定要记住,删除操作将为每个侵入性链接字段调用析构函数,以从链表中删除该元素。
如果要删除的对象已经从所有链表中取消链接,这是没有问题的。但是如果对象仍链接到一个链表,则必须使用锁来防止竞态条件出现,这有些依次从差到好的的解决方法。
1
2
3
4
5
6
7
8
9
10
11
| // Wrap destructor with a lock to avoid race condition
// Downsides:
// lock held while calling destructor
// lock held during memory free
void threadsafe_delete_person (person *ptr) {
s_personlock.EnterWrite();
{
delete ptr;
}
s_personlock.LeaveWrite();
}
|
1
2
3
4
5
6
7
8
9
10
11
12
| // Wrap unlink with lock to avoid race condition.
// Avoids downsides of the solution above, but
// Unlink() will be called again safely but
// unnecessarily in the TLink destructor.
void threadsafe_delete_person (person *ptr) {
s_personlock.EnterWrite();
{
ptr->link.Unlink();
}
s_personlock.LeaveWrite();
delete ptr;
}
|
1
2
3
4
5
6
7
8
9
10
11
| // Same as above, but less fragile; since the
// unlinking is done in the destructor it is
// impossible to forget to unlink when calling
// delete
person::~person () {
s_personlock.EnterWrite();
{
link.Unlink();
}
s_personlock.LeaveWrite();
}
|
1
2
3
4
5
6
7
8
9
10
| // Same as above but reduces contention on lock
person::~person () {
if (link.IsLinked()) {
s_personlock.EnterWrite();
{
link.Unlink();
}
s_personlock.LeaveWrite();
}
}
|
链接和列表的分配和复制构造
无法复制构造或分配链接到侵入性列表中的对象,也不能对链表本身进行同样的操作。实际上,你不会遇到这种限制。对于需要将元素从一个链表移动到另一个链表的特殊情况,可以编写一个函数以将元素从一个链表拼接到另一个链表。
为什么不使用 boost 的侵入式链表
boost 实现了一个跟我的侵入式链表相似的侵入式链表,它设计的目标是解决你遇到的每一个链表问题,因为使用起来是比较费劲的。我认为他们把这个搞得复杂是不必要的。
当你你阅读源代码,我希望你能直接找到它。首先,包括注释和MIT许可证在内的整个侵入式链表的总行数少于500行。
将其与 boost intrusive list.hpp(确实具有更多功能)进行比较,它有1500行,这其中还不不包括十一个辅助头文件,这些辅助头文件充满了所有不可读的现代 C++ 模板下的奇淫技巧。
一些 std::list 会崩溃的用例
这些例子是我在 ArenaSrv 和 StsSrv 中实现的代码,它们是我编写的服务器框架,几乎用于所有的 Guild Wars 服务(GW1和GW2),但为了清楚和简洁而进行了重写。
该代码旨在防止被称为 Slowloris 的网络攻击。Slowloris 是指逐渐将大量 socket 连接到单个网络服务,直到最终使服务器饱和,此时服务器通常会停止正常运行。尽管许多其他网络服务也存在类似问题,但 Apache Web 服务器特别容易受到 Slowloris 的攻击。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
| //*********** SLOWLORIS PREVENTION FUNCTIONS ***********
// Mark connection so it will be closed "soon" unless
// a complete message is received in the near future
void Slowloris_Add (Connection * c) {
s_pendingCritsect.Enter();
{
// List is kept in sorted order; newest at the tail
s_pendingList.LinkTail(c);
c->disconnectTime = GetTime() + DEFEAT_SLOWLORIS_TIME;
}
s_pendingCritsect.Leave();
}
// Remove connection from "close-me-soon" list
void Slowloris_Remove (Connection * c) {
s_pendingCritsect.Enter();
{
s_pendingList.Unlink(c);
}
s_pendingCritsect.Leave();
}
// Periodically check "close-me-soon" list
void Slowloris_CheckAll () {
s_pendingCritsect.Enter();
while (Connection * c = s_pendingList.Head()) {
// Since the list is sorted we can stop any
// time we find an entry that has not expired
if (!TimeExpired(GetTime(), c->disconnectTime))
break;
s_pendingList.Unlink(c);
c->DisconnectSocket();
}
s_pendingCritsect.Leave();
}
//*********** SOCKET FUNCTIONS ***********
void OnSocketConnect (Connection * c) {
Slowloris_Add(c);
}
void OnSocketDisconnect (Connection * c) {
Slowloris_Remove(c);
delete c;
}
void OnSocketReadData (Connection * c, Data * data) {
bool msgComplete = AddData(&c->msg, c->data);
if (msgComplete) {
Slowloris_Add(c);
ProcessMessageAndResetBuffer(&c->msg);
}
}
|
你不会想用 std::list 去解决这种类型的问题,因为每次有必要从“close-me-soon”链表中删除连接时,都需要遍历链表的50%(平均。)由于某些 Guild Wars 1 服务在一个进程中建立了了多达2万的连接,因此这将需要扫描1万个节点,这不是一个好主意!
我站在巨人的肩膀上
我没有发明这种链表技术。我第一次遇到它是在 Mike O’Brien 的暗黑破坏神代码中,该代码包含在 Storm.dll 中。当我和 Mike 与Jeff Strain 一起创建 ArenaNet 时,Mike 编写的第一个代码是该链表代码的更好版本。
离开 ArenaNet 后,我发现在使用侵入式链表进行了十年编码之后(并且随之而来的是不必担心愚蠢的链表错误)我需要重新实现代码,因为没有更好的替代方法了(尽管有 boost)。随之而来的是反复试验!
为了避免这种不断的重写,我使用 MIT 许可开源了代码,这意味着您可以不受商业限制地使用它。
结论
那么,这就是关于侵入式列表用途的解释。它们非常适用于编写更可靠的代码,因为它们会自行清理(注意:多线程代码除外)。
《Guild Wars》的编程团队包括了超过十名刚从大学毕业的编程人员。如果我们让他们使用 std::list 编写游戏引擎的代码,缺陷数量可能会更高——这并不是对这些程序员的任何冒犯,他们都是很优秀的人才。通过为他们提供这样的工具,我们成功地编写了650万行代码,这对于一款游戏来说是非常庞大的规模,并且非常稳定可靠。
优秀编程的一个重要目标是提高可靠性。通过创建易用可靠的集合类,我们可以在这个方面迈出一大步。