golang 1.9.2 升级至 1.13.5 导致 cpu 使用率大幅上升
文章目录
现象
负责的规则引擎服务之前一直使用 golang 1.9.2 出于对性能及开发效率的考虑,计划升级至 1.13.5。修改版本至1.13.5后在 sim 和 pre 等环境部署,观察程序运行一切正常,gc 耗时和内存使用也均有下降。线上机器部署完毕后,发现平峰期 gc 耗时和 cpu 使用率小幅上涨,高峰期 gc 和 cpu 使用率有大幅上涨。高峰期对外接口耗时有明显上涨,cpu idle 也已经达到报警阈值。很遗憾现场截图被我搞没了
分析
go tool pprof
在线上机器高峰期使用 pprof 采集 cpu 信息
cum:某函数消耗的 cpu 时间
flat :某函数本身消耗的 cpu 时间,排除了函数内调用其他函数的耗时
| 1.9.2 | 1.13.5 | |
|---|---|---|
| 按照 flat 降序排列 |  |  |
发现 runtime.(*lfstack).pop 函数在1.13.5版本消耗了大量的 cpu,而在1.9.2甚至没有出现
go tool trace
在线上机器高峰期使用 trace 跟踪程序运行轨迹
| 1.9.2 | 1.13.5 | |
|---|---|---|
| trace |  |  |
| minimum mutator utilization (没找到官方翻译,以下简称 mmu)图。这个图同样由 trace 工具生成 | 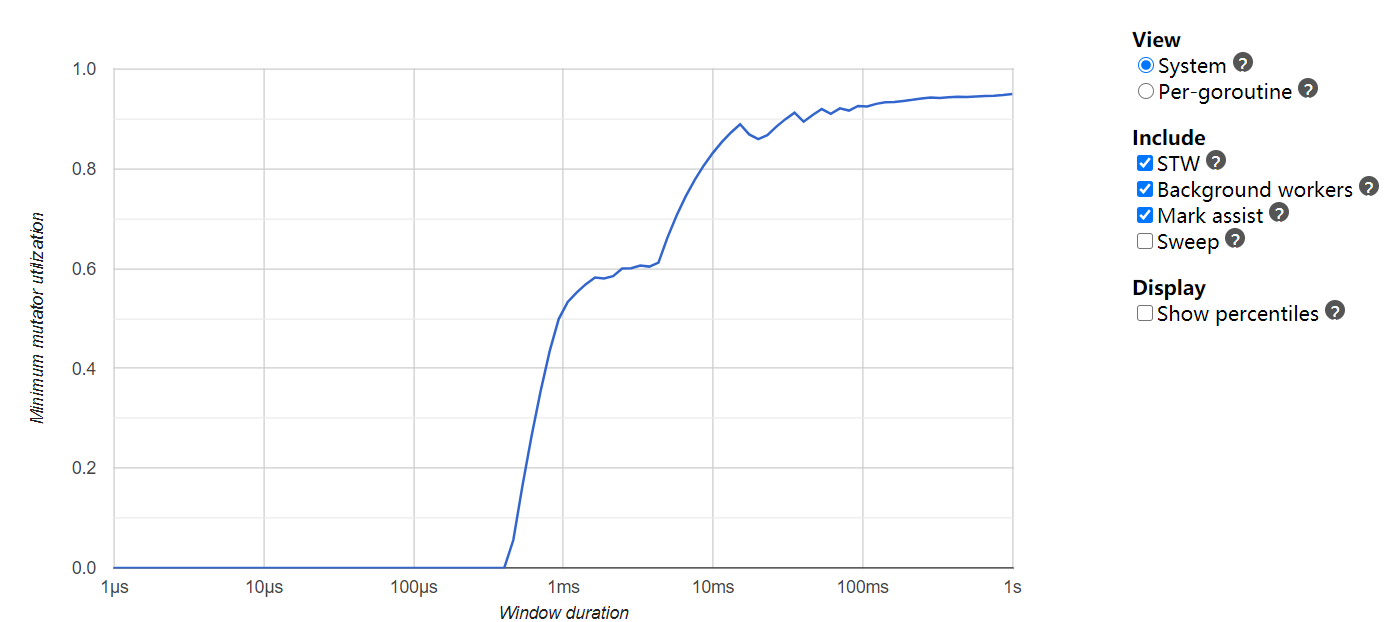 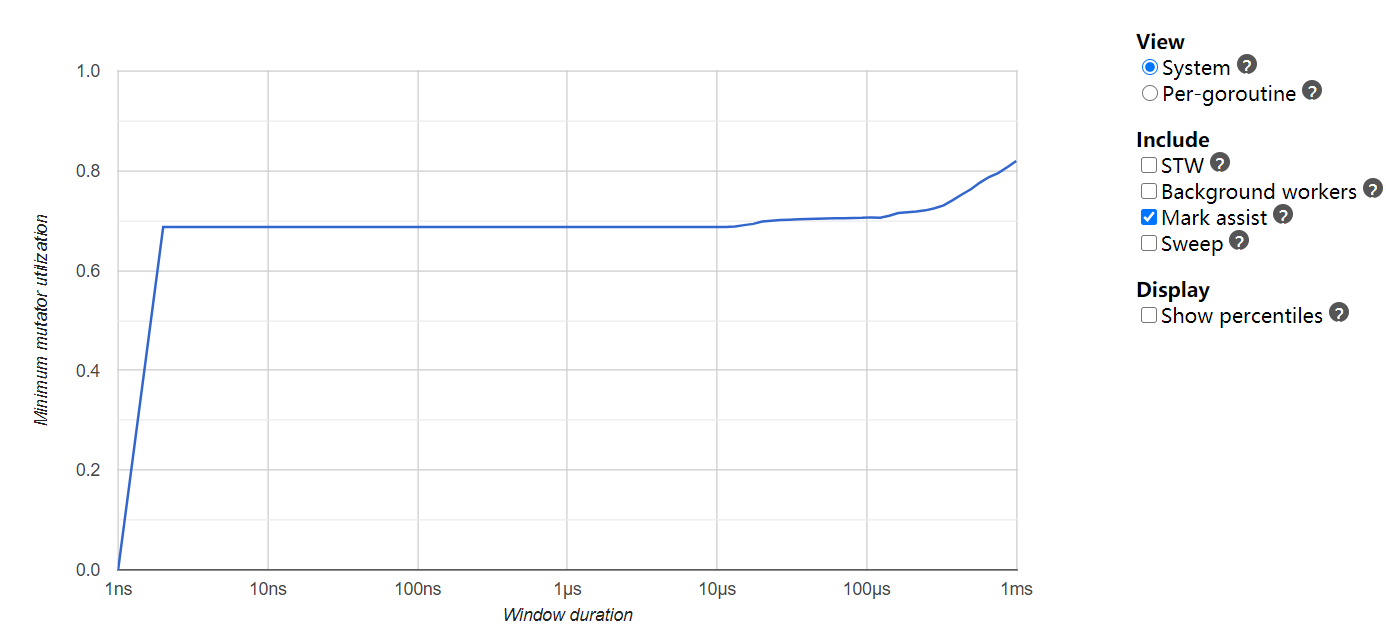 |   |
| graph | 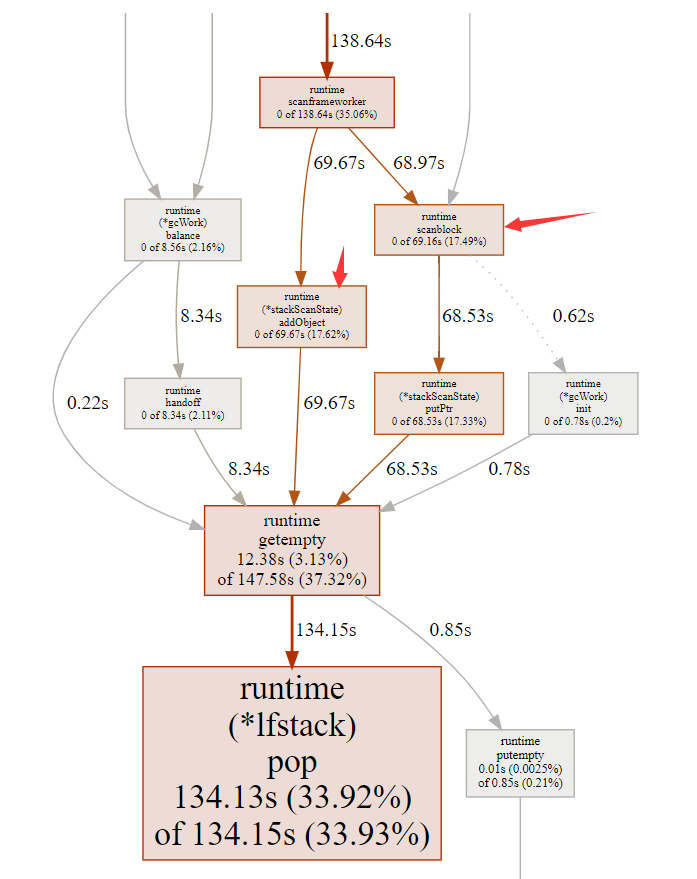 |
trace 按照时间顺序记录了程序所有 goroutine 在被 trace 期间的执行情况。时间刻度在最上方
mmu 图横轴为时间窗口长度,记为 x。纵轴为 cpu 执行用户自己的代码的时间与 cpu 执行整个程序所使用的时间的比值,记为 y。f(x) 的值为在所有的 x 下最小的 y。
通过上面的表格发现
1.13.5 大量 goroutine 在 gc 时进入了长时间的辅助标记(mark assist,图中浅绿色部分)阶段,而1.9.2几乎没有。mmu 图也量化的证明了在 1ms 以上的时间窗口,单看 mark assist,cpu 实际“有效”使用率只有30%不到。
分析目标函数 runtime.(*lfstack).pop
配置好源码路径后,使用 pprof 在 view->top 下选中目标函数,选择 view->source,可以直接查看每行代码的时间消耗。如下图
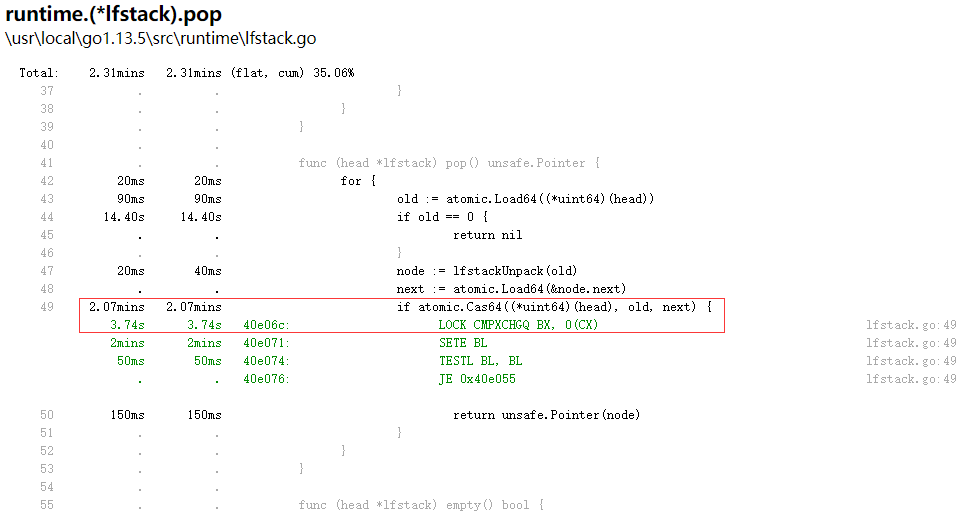
发现这是一个利用 cas 实现的无锁栈的 pop 方法,大部分时间消耗在了红框内语句,证明当时的并发竞争比较严重,if 内的条件返回 false 的概率很大。
通过 pprof 的 view->graph 找到调用 pop 方法总耗时最大的父函数,并对比 github 的提交记录找到当时的 commit 记录,发现是为了解决 issues#22350,并在代码注释中找到了设计文档 GC scanning of stacks。
综上,发现这个修改是为了解决栈空间释放不及时的问题,示例代码如下:
| |
curr 在 step 1 获得到的地址,在 for 的第一次 step 3 之后,地址指向的 Node 实例就不会被任何对象引用,按理说应该会在 gc 时被回收,但在1.12之前,这段程序实际运行结果是内存不断上涨,所有 Node 实例都没有被释放。
原因是 1.12 前的 gc 在扫描时发现 curr 指向的 Node 是分配在栈上,就会假定这个对象一直存活,不会进一步去扫描它。这就导致了类似示例代码的程序内存一直上涨,最后 OOM。
1.12增加了对这些栈对象的扫描,在发现这个指针变量指向的是栈空间的地址后,会将这个地址放入上面提到的 lfstack 中,用作后续扫描。
根因
升级至1.13.5版本产生的 gc 耗时和 cpu 上涨是由于1.12版本增加的对栈对象的精确扫描导致。
复现
复现条件:
- 有较多的指向栈对象的指针
- 并发 goroutine 多
- cpu 核数多
cpu 核数和 goroutine 数量越多应该越容易复现。
1.13.5 gc 阶段出现大量辅助标记的 goroutine 猜测是因为 lfstack.pop 占用了过多 cpu,全职 gc 的 goroutine 标记速度被拖慢,而进入辅助标记的 goroutine 又导致了 lfstack.pop 占用更多 cpu,进入恶性循环。
解决方案
可能的解决方案有如下两种
- 扩容,降低单机的并发数量
- 减少代码中栈对象指针的数量
方案1比较简单粗暴,但很有效,只是不太治本,最一开始初步定位问题后,就是采用的这个方案临时解决了
方案2的话比较治本,但需要定位具体是哪些栈对象引起了问题,比较困难。
针对方案2比较直观的想法是如果能在每次扫描时把所有扫描对象打印出来就好了。
于是通过继续阅读 gc 相关部分代码,发现文件 src/runtime/mgcstack.go 中有一个布尔变量 stackTraceDebug 控制了一些栈相关的 debug 信息输出,可以打印一些 debug 信息,协助寻找栈对象指针。
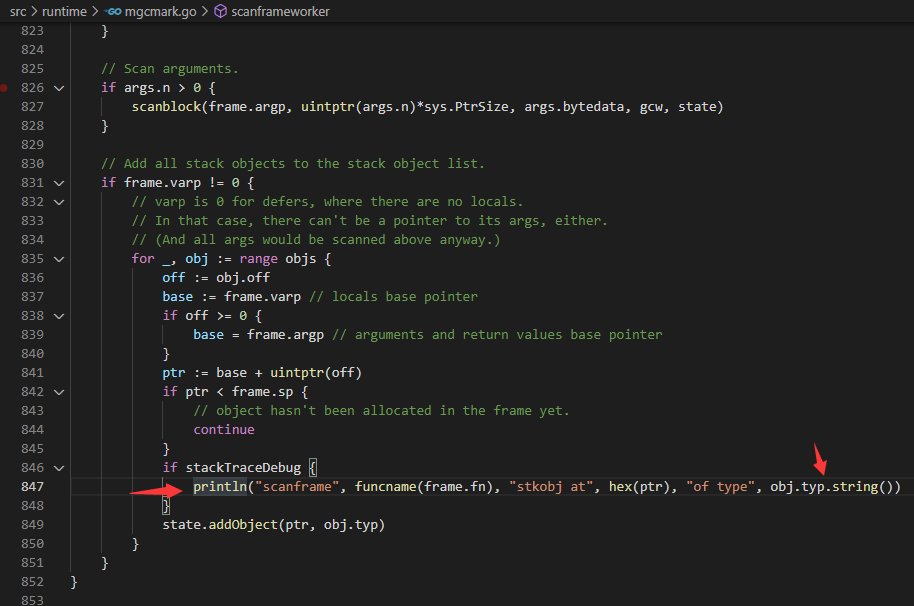
tackTraceDebug 默认为 false,修改 stackTraceDebug 为 true 后,有多处日志的输出,在本例中主要关注红色箭头这一行的输出,会打印出具体的对象类型。注:runtime 内 println 会输出到标准错误输出
上线效果
修改 stackTraceDebug 后,重新编译上线,通过输出分析,发现大部分扫描集中于一个协程池内的某个对象(整体代码结构与上面的链表例子如出一辙),通过对历史数据分析,判断目前协程池并不需要,于是直接去掉协程池并上线。整体效果比较显著,以 hna 集群为例
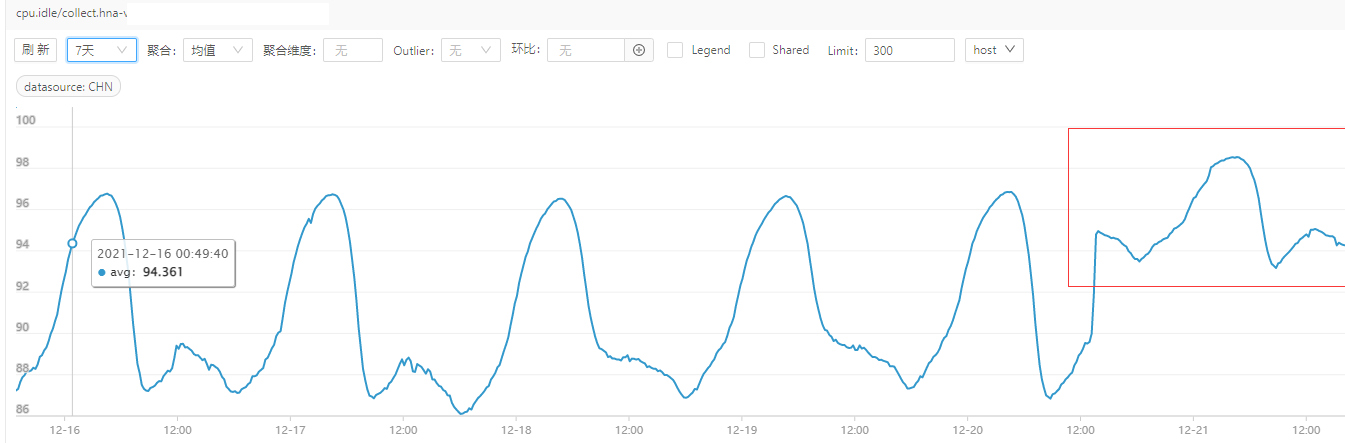 集群 cpu.idle 有非常明显的提升,在高峰期提升尤为明显
集群 cpu.idle 有非常明显的提升,在高峰期提升尤为明显