线上 c++ 服务内存泄漏排查
文章目录
1 背景
同事某日收到某服务(c++编写)内存报警,具体内存使用情况如下图
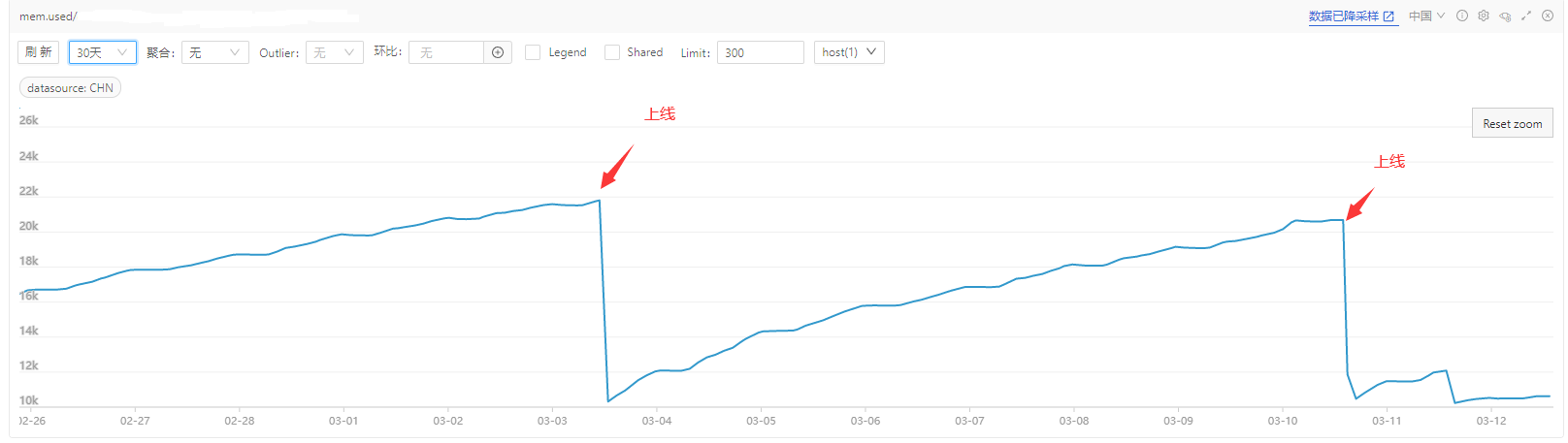 可以看到有非常明显的内存持续性上涨,初步怀疑为内存泄漏。以下在 sim 环境对问题进行复现和排查
可以看到有非常明显的内存持续性上涨,初步怀疑为内存泄漏。以下在 sim 环境对问题进行复现和排查
2 排查
2.1 常见内存泄漏排查工具
| Valgrind | AddressSanitizer | Gperftools | BCC |
|---|---|---|---|
| https://valgrind.org/ 是一个非常老牌的工具组,其中的 memcheck 可以用来检测内存泄漏。但使用上不是很方便,是侵入式的,而且会对进程的性能有较大影响 | https://github.com/google/sanitizers/wiki/AddressSanitizer 是 gcc 4.8 开始内置支持的一个内存错误检测工具,仍然是侵入式的,对进程影响稍小(至少官方文档是这么说的),可惜在我测试的时候 gcc 4.8.2 好像仍然不能很好的支持 | https://github.com/gperftools/gperftools 是一组高性能的支持多线程 malloc() 实现的集合,并附带了一些性能分析工具。tcmalloc 大家应该比较耳熟,前面指的就是它。同样是侵入式的,可以把它链接到项目中,复用 tcmalloc 的能力去排查内存泄漏的地方,对进程影响稍小。同理 jemalloc 也有类似的工具,用哪个都行 | https://github.com/iovisor/bcc 本身是一个用于创建高效内核跟踪和操作程序的工具包,基于 eBPF 功能实现。eBPF 是在 Linux 3.15 开始出现的一个新特性 ,而 bcc 内的大部分工具(包括内存泄漏的检测)都需要 Linux 4.1 及更高版本。它最大的优点是非侵入式,同样对进程影响也较小,应该是在条件满足时的最佳使用工具。不过很遗憾,目前线上系统 linux 内核版本都是3,无法使用。eBPF 虽然诞生的很早,但是最近几年才火起来的技术,它可以实现很多非常强大并且令人兴奋的功能,以后基于它去做大规模常态化的系统监控和 debug 可能会是一个趋势 |
综上选择 Gperftools 去做分析
2.2 Gperftools
gperftool 的编译依赖于 libunwind,需要先把这个库装好,过程略过。
编译完成后会生成 tcmalloc 动态库和 pprof 脚本工具(用来解析生成的分析文件)
后续生成 pdf 格式的调用关系图的话,需要提前安装 dot 和 ps2pdf
2.2.1 启动服务
将 tcmalloc.so 编译好后复制到对应环境,然后执行
| |
LD_PRELOAD 这个环境变量可以让进程优先从这里加载动态库
执行后服务就启动起来了,默认每当目标进程分配 1GB 的内存后,就会生成一份当前进程内存的分析文件(包含了调用路径和分配内存大小等),这个文件挺小的,不用担心硬盘撑不住。也可以不按照 1GB 间隔,通过环境变量可以调整它的大小,配置参数参考 https://gperftools.github.io/gperftools/heapprofile.html
2.2.2 分析内存分析文件
观察服务内存使用情况,等使用率上来后执行
| |
- –pdf:生成 pdf 格式文件。这有个冷知识,pdf 是一种跨平台的文件格式
- –base:已 base 后紧跟着的分析文件为基准比较两个分析文件的内存分配差值
生成的 pdf 内最重要部分如下

这个框的大小直观的代表了分配内存的多少,越大越多,数字代表具体分配数值,整体各部分的含义和 cpu 的分析图是一致的,只不过这里换成了内存。
可以很容易的看出 _S_create 这个函数内分配了最多的内存。一般来说如果泄漏的时间够久,那分配最大的地方大概率就是内存泄漏的地方,但考虑到 sim 环境与线上环境的差异(比如上下游流量等),且无法长时间占用等因素,暂时对这个泄漏点持谨慎态度,先顺着这个分析。把这个路径单独截出来
可以看到是 brpc 收取 thrift 数据并反序列化的一段过程。在这个问题的排查过程中,实际上是按照路径把代码都看了一遍,但最后发现跟这个问题关系不大,这部分就略过。主要关注红色箭头的那个调用,即进入标准库前的最后一个用户层(相对于标准库)函数 readStringBody,这个已经到 thrift 层了,可以排除 brpc 的问题,源码截图如下

红色箭头处就是接下来要进入的标准库函数,StrType 在这里被实例化为 std::string。上一行的 borrow 在取名上有一点误导,一开始以为是为了重复利用内存而做的内存池,borrow 就是借出一段可用的空内存。但实际上有一些差别,源码就不展开看了,反正最后确认这个 trans_ 的 buffer 并不是空的而是已经含有了本次要处理的所有 thrift 的数据,获得到的 borrow_buf 就是指向了要被放到 str 这个 string 内的数据的指针。分析到这,有两个初步的可能
- str 直接复用了 borrow_buf 这块内存,而这块内存没有释放导致泄漏
- str 拷贝了一份数据放到自己的新分配空间内,str 新分配的内存一直没有释放导致泄漏
要确定这两个问题就要看一下 assign 的实现了,这部分调用链路为 assign->_M_replace_safe->_M_mutate→_Rep::_S_create 截图如下。这里有个阅读标准库的小技巧,先把它按照熟悉的代码格式格式化一下,阅读难度会下降不少
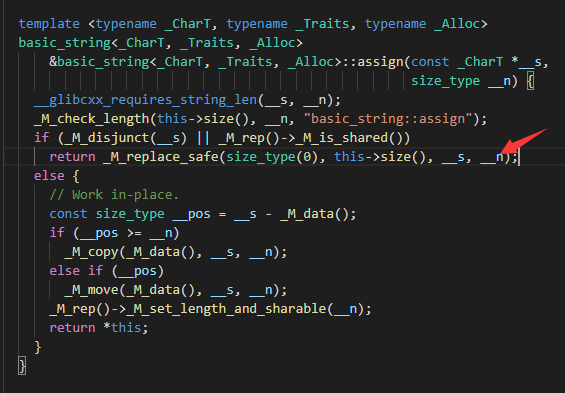


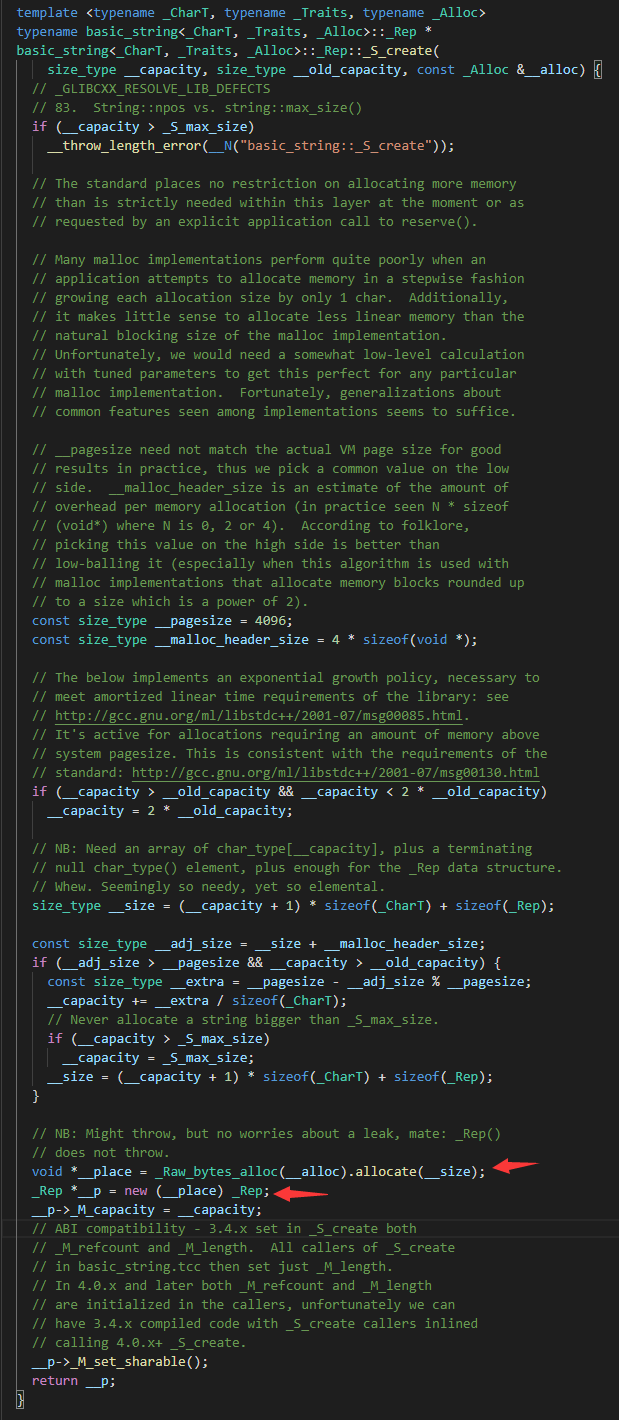
可以发现确实是在 _S_create 内分配了一段内存并进行了初始化,然后通过 _M_copy 函数复制了一份数据。这样就可以否定刚才的观点1。接下来就要看看为什么这个 str 变量没有释放自己的内存,通过观察调用路径上的函数,可以发现是在反序列 C(马赛克)e 这个字段,查看 idl 很幸运的发现这个类里只有一个 string 类型的变量,截图如下

上面那个 map 虽然也有 string,但如果是它的话代码路径会多一个 map 的专门解析函数。接下来在业务代码里肉眼跟踪一下他的生命周期,发现在反序列化之后,与另一个变量(pbDataChannel_)做了 swap,如下

接下来应该继续确认 swap 的实现了,因为这个不复杂,这里就不展开了,结论就是 swap 只交换了这两个 string 变量内指向实际数据的指针,也就是上面通过 _S_create 分配的空间现在交由这个 pbDataChannel_ 变量管理了。
继续跟踪 pbDataChannel_ 的生命周期,先看下在代码内的声明,截图如下

可以发现是在某类内的一个固定长度的 string 数组成员变量,而这个类实例化后的对象都是放在一个对象池内做了复用,从对象池取用和放回时都不会对 pbDataChannel_ 变量做任何操作,而业务代码上对 pbDataChannel_ 的写只有这一个 swap,这样会导致对象池内的 pbDataChannel_ 数组中存有实际数据的 string 会越来越多,进而引起内存只增不减(业务上不会出错的原因是因为有单独维护数组的有效索引),看起来问题比较清晰了,虽然一开始对这个点持谨慎态度,但至少现在可以证明这块一定是有问题的。
3 根因总结
内存泄漏是由 string 数组变量 pbDataChannel_ 的内存空间没有释放导致
4 解决方案
知道原因后解决方案就很简单了,在这个对象池初始化这个对象的地方加上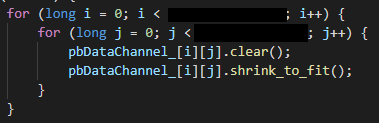
就可以了。先调用 clear 逻辑上清空 string,然后调用 shrink_to_fit 让这个 string 把多余的空间释放。当然这种解决方式还是有点粗暴,刚好业务上并没有对这个字段有什么操作,是一个透传字段,所以应该影响不显著,后续如果有问题会做一些更精细的调整。这块清空其实也有好几种方法就不一一枚举分析了。
5 上线效果
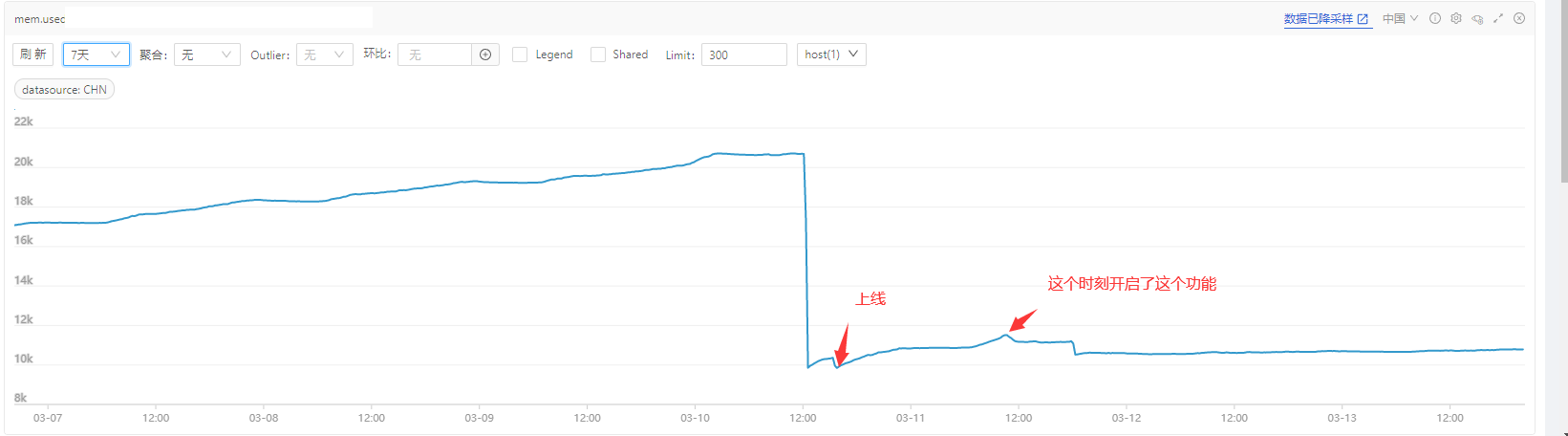
效果显著,内存泄漏被修复